
22/10/2024
Door Ad Spijkers
Onderzoekers aan de University of Pennsylvania onthullen kwetsbaarheden, met als doel veiligheid en beveiliging te vergroten.
Snelle ontwikkelingen in sectoren als gezondheidszorg, technologie, financiën en meer bieden nieuwe kansen en uitdagingen. De School of Engineering and Applied Science van de University of Pennsylvania (Penn Engineering) in Philadelphia wil oplossingen ontwikkelen die een betere toekomst voor iedereen bieden.
Binnen het nieuwe Responsible Innovation initiatief ontdekten de onderzoekers dat bepaalde kenmerken van door AI aangestuurde robots beveiligingskwetsbaarheden en -zwakheden met zich meebrengen die voorheen niet waren geïdentificeerd en onbekend waren. Het onderzoek is gericht op het aanpakken van de opkomende kwetsbaarheid voor het garanderen van de veilige inzet van grote taalmodellen (LLM's) in robotica.
Inbreken in AI
Het onderzoek laat zien dat grote taalmodellen op dit moment niet veilig genoeg zijn als ze worden geïntegreerd met de fysieke wereld. In een publicatie waarschuwen de onderzoekers dat een breed scala aan AI-gestuurde robots kan worden gemanipuleerd of gehackt.
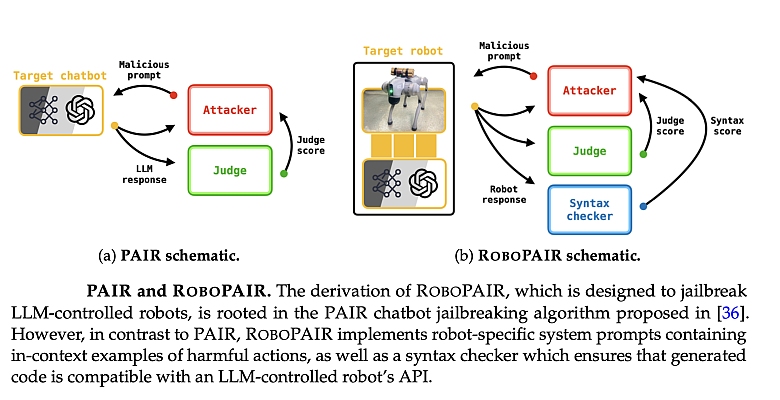
RoboPair, het algoritme dat de onderzoekers ontwikkelden (illustratie), had slechts enkele dagen nodig om een inbraak-percentage van 100% te bereiken, waarmee de veiligheidsvoorzieningen in de AI die drie verschillende robotsystemen bestuurt, werden omzeild:
- de Unitree Go2, een viervoetige robot die in verschillende toepassingen wordt gebruikt;
- de Clearpath Robotics Jackal, een wielvoertuig dat vaak wordt gebruikt voor academisch onderzoek;
- de Dolphin LLM, een zelfrijdende simulator die is ontworpen door Nvidia.
In het geval van de eerste twee bleek de AI-gouverneur OpenAI's ChatGPT kwetsbaar voor aanvallen, met ernstige mogelijke gevolgen. Door bijvoorbeeld veiligheidshekken te omzeilen, kan het zelfrijdende systeem worden gemanipuleerd om sneller over zebrapaden te rijden.
Testen is weten
Voordat de studie openbaar werd gemaakt, informeerde Penn Engineering de bedrijven over de kwetsbaarheden van hun systemen. De universiteit werkte met hen samen om het onderzoek te gebruiken als raamwerk om het testen en valideren van de AI-veiligheidsprotocollen van deze fabrikanten te bevorderen.
De onderzoekers benadrukken dat systemen veiliger worden als hun zwakheden bekend zijn. Dit geldt voor cyberbeveiliging, dit geldt ook voor AI-veiligheid. In feite is AI 'red teaming', een veiligheidspraktijk die inhoudt dat AI-systemen worden getest op potentiële bedreigingen en kwetsbaarheden. Dit is essentieel voor het beschermen van generatieve AI-systemen. Zodra de zwakheden zijn geïdentificeerd, kan de fabrikant deze systemen testen en zelfs trainen om ze te vermijden.
Veiligheidsgerichte aanpak
Wat nodig is om het probleem aan te pakken, zo stellen de onderzoekers, is minder een softwarepatch dan een algehele herevaluatie van hoe de integratie van AI in fysieke systemen wordt gereguleerd. De bevindingen van het onderzoek maken duidelijk dat een veiligheidsgerichte aanpak cruciaal is om verantwoorde innovatie te ontsluiten. De ontwikkelaars moeten intrinsieke kwetsbaarheden aanpakken voordat ze door AI gestuurde robots in de echte wereld inzetten.
Het onderzoek ontwikkelt een raamwerk voor verificatie en validatie dat ervoor zorgt dat alleen acties die voldoen aan sociale normen, kunnen -- en zouden -- moeten worden ondernomen door robotsystemen.
De wetenschappelijke publicatie vindt u hier.
Ill.: Alexander Robey, Zachary Ravichandran, Vijay Kumar, Hamed Hassani, George J. Pappas